
Gartner’s 2022 Predictions
Engineering Trust – Privacy-Enhancing Computation
We are living in an age of increased surveillance and decreased cyber-privacy. That’s not necessarily a bad thing, but it makes people uncomfortable that – for example – Google or Microsoft could have access to a wide range of data that we might not necessarily have allowed them access to. But should we be protesting this data collection or trying to use the development for a better use?
That’s exactly what companies like Huawei and DeliverFund are doing – they are developing ways to make data more useful with AI, advanced analytics, and new approaches to insights but at the same time making it more secure. The future of data management and security is a bright one, especially for privacy conscious individuals who are already using the likes of GrapheneOS and a hardened web browser.
Understanding privacy-enhancing computation
As previously mentioned, privacy-enhancing computation (PEC) is a new way of approaching the way that we use data. Big data is incredibly useful for discovering business insights, spotting cybersecurity issues, and many other applications, but there is a growing concern about how that data is stored, accessed, and – potentially – infiltrated by the adversary.
Because of that, a number of tech companies around the world are focusing on engineering greater trust in their data handling capabilities. Some of these companies are using it to improve user safety and assist security professionals (such as Huawei) and others are revolutionizing around approach to human interest issues such as DeliverFund’s assistance in ending human trafficking.
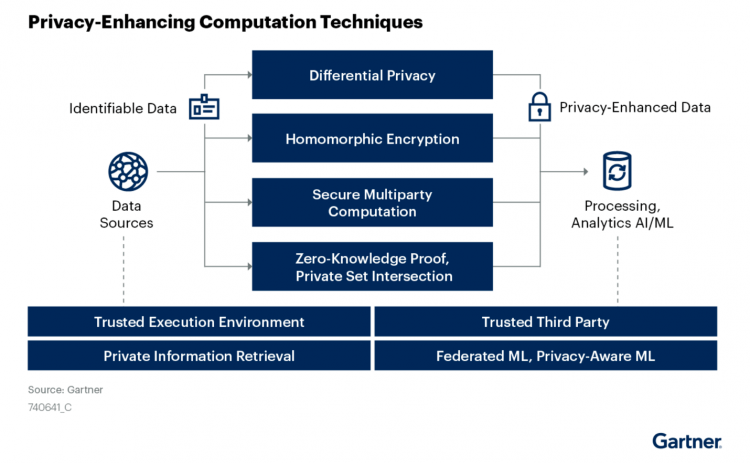
As you can tell, this approach is going to be a pretty broad subject. But there are a number of key facets that are in common throughout. These include:
- Differential privacy, using algorithms to add controlled randomness to any given dataset.
- Homographic encryption (HE), allowing computation on and analysis of data that has been encrypted without accessing the decryption keys.
- Secure multiparty computation, splitting the computation workload across multiple “parties” to stop any individual from accessing the information in its totality.
- Private set intersection (PSI), also referred to as zero-knowledge proof PSI, where two private sets of data are analyzed and only the necessary, overlapping information is shared between the parties.
These are then supported, according to Gartner, by the following four principles:
- Trusted execution environment, an environment where code can be executed with a high level of trust that the surrounding environment can ignore or escape threats.
- A trusted third party.
- Private information retrieval, allowing clients to access data from a given dataset without the owner of the data being notified exactly what is being accessed.
- Federated machine learning supported by privacy-aware machine learning.
As an approach to data management, the intention is that not only the data itself is better protected, but also that whoever is accessing or owning the data has less control and less opportunity to monitor it. But wait, why does that sound like a bad thing? Well, it would be if the entire process relies on intelligent machine learning and computation processes to share, organize, and protect all data contained within.
How do you implement privacy-enhancing computation?
Depending on your security needs and how much your organization can afford, there is actually a hierarchy of different privacy-enhancing technologies that security professionals and data managers can refer to:
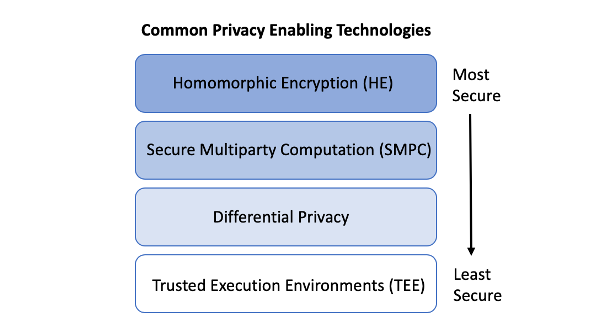
Obviously, implementing HE would be an excellent way to manage your data and ensure that data is locked down, but this isn’t always possible for everyone. Instead, asking yourself the following questions may be a way to determine what kind of technologies you need and how you should approach adding them to your arsenal.
- Does my organization need to hide who is communicating sensitive messages?
- How does obfuscation aid in defending our systems?
- Who has access to our personal data (e.g., PHI, PII) and do we need to protect it?
- Is zero-knowledge proof something that we could include in our services?
- Is our approach to encryption strong enough?
Although these are only the beginnings of the issues that data scientists and security professionals will have to consider when moving to a PEC-style approach to information management, they are an excellent jumping-off point for people opening their eyes to the world of ML-assisted, intelligent data management.
Want to find out more?
Obviously, this topic is much larger than we can handle in ~800 words, so check out the following resources:







{kind=link}